Machine Learning – căn bản của căn bản: Cách sử dụng cơ bản của Numpy – thư viện không thể thiếu trong tính toán ma trận
Đã mấy tháng trôi qua, và giờ tôi lại có hứng thú dịch tiếp serie Machine learning cơ bản được đăng tải trên báo Atmarkit (các bạn có thể xem bài gốc ở đây: Pythonで始める機械学習入門). Ở bài trước thì tôi đã giới thiệu với các bạn trình soạn thảo đa chức năng trên nền web Jupyter Notebook, và từ bây giờ chúng ta sẽ dùng nó để demo các ví dụ có trong bài. Bài viết hôm nay sẽ giới thiệu với các bạn cách sử dụng cơ bản của một thư viện không thể thiếu trong tính toán ma trận – Numpy/SciPy.
Sử dụng ma trận (mảng 2 chiều) thể hiện số lượng đặc trưng của mỗi sample trong máy học
Thông thường, ma trận data được sử dụng trong máy học thì các hàng (hàng ngang) sẽ biểu biễn sample, các cột (hướng dọc) sẽ đối ứng với lượng đặc trưng tương ứng. Ví dụ, ở data sample hay được sử dụng ở 「Scikit-learn」 mà đã giới thiệu ở bài đầu tiên, là iris pattern. Nếu trích xuất 5 hàng trên data này, ta sẽ có ma trận như dưới đây.
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2]])
Đây là data tập hợp 4 cái của iris pattern. Một hàng thể hiện một bông hoa của pattern, và ở đây, 5 data của pattern được sắp xếp. Chữ số được xếp ở hàng ngang thể hiện kích thước của 4 cái (độ dài của Sepal, chiều rộng, độ dài của cánh hoa, chiều rộng).
Thông thường, khi sử dụng thuật toán máy học, rồi thực hiện dự đoán, phân loại, và clustering (phân cụm), v.v… thì phải chuẩn bị sẵn data (mảng 2 chiều) có dạng như vậy.
Numpy và SciPy
Numpy là package cơ bản của tính toán khoa học, cung cấp mảng tính toán hiệu quả cao, chức năng tính toán ma trận, biến đổi Fourier, v.v…
SciPy là thư viện high-level của Numpy, cung cấp các công cụ tính toán khoa học kỹ thuật tiêu chuẩn.
Vì cả NumPy và SciPy đều rất hiệu năng cao, nên ở trong serie này, tôi sẽ tập trung vào quan điểm là công cụ dành cho máy học, mà giới thiệu cách sử dụng hữu ích trong việc xử lý data tối thiểu. Xin hãy xem thêm giải thích bao quát hơn ở document này. Trong bài viết này sẽ tập trung vào NumPy, ở bài tiếp theo, tôi sẽ giới thiệu SciPy.
Từ bây giờ, chúng ta sẽ giả định rằng Numpy được import như sau.

Thao tác cơ bản với mảng bằng NumPy
Bản thân Python thì có kiểu dữ liệu là list, tuy nhiên lại không có kiểu dữ liệu tương ứng với mảng. Kiểu list thì có lợi điểm là kiểu dữ liệu của các yếu tố không cần phải giống nhau, và có tính linh hoạt là có thểm phần tử thoải mái, tuy nhiên, ở điểm tốc độ tính toán khi tính toán số học thì kiểu dữ liệu mảng của NumPy sẽ tốt hơn.
Tạo mảng từ kiểu dữ liệu list – numpy.array
Mảng 1 chiều thì tuy là giống list, nhưng khác nhau ở điểm là toàn bộ các yếu tố phải có kiểu dữ liệu giống nhau. Ở trong ví dụ dưới, thì bằng việc sử dụng 「numpy.array」, mảng một chiều có thể dễ dàng được tạo ra.

Ngoài ra, giống như list việc truy cập phần tử thứ i trong mảng 1 chiều 「a」 là 「a[i]」. Tuy nhiên, trong Python thì index bắt đầu từ 0, vậy nên ta sẽ gọi phần tử lần lượt là 「thứ 0」 「thứ 1」. Tên gọi 「hàng i」「cột j」 trong trường hợp mảng 2 chiều cũng tương tự.
Thêm nữa, 「a.shape」 trong In[4] thì biểu thị hình thù của 「a」 (kích thước dài rộng), còn 「a.dtype.name」 trong In[5] biểu thị tên gọi kiểu dữ liệu của yếu tố.
Thêm nữa, 「a.shape」 trong In[4] thì biểu thị hình thù của 「a」 (kích thước dài rộng), còn 「a.dtype.name」 trong In[5] biểu thị tên gọi kiểu dữ liệu của yếu tố.
Tạo mảng lấy cấp số cộng làm yếu tố – numpy.arange
Để tạo mảng có yếu tố là cấp số cộng, ta dùng 「numpy.arange」.

Chỉ định kiểu phần tử của mảng bằng đối số đặt tên 「dtype」
Kiểu của phần tử trong mảng được set một cách tự động, tuy hiên trong In[11] dưới đây, thì có thể chỉ định rõ ràng bằng đối số đặt tên 「dtype」.

Tạo mảng 2 chiều từ list của list
Việc chuẩn bị sẵn data giống 「Iris」 vừa rồi, thì cách biến đổi từ list của list như In[12] là tiện lợi nhất. Vì việc thêm phần tử trong list khá dễ dàng, nên nếu tạo list môt lần, rồi sau đó biến đổi thì rất dễ thực hiện.

Biến đổi input từ file CSV thành mảng
Trong code dưới đây, sẽ biến đổi input từ file CSV thành mảng.
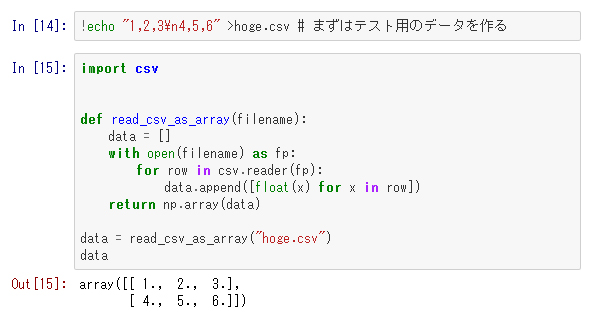
Trong thực tế, nếu mục đích là import file CSV, thì bằng việc sử dụng 「numpy.genfromtxt」 và 「Pandas」 library thì sẽ tiện lợi và xử lý nhanh chóng, tuy nhiên ở đây thì bằng ví dụ xử lý input chung chung, tôi đã mất công set bằng tay. Chung chung thì vì không hiểu input sẽ trở thành cái gì, nên code ví dụ này sẽ khá hữu ích.
Tạo hàng có toàn bộ phần tử là 0 – numpy.zeros, tạo hàng có toàn bộ phần tử là 1 – numpy.ones
Thường thì cần phải có một mảng mà chứa các giá trị được định trước. Ma trận có toàn bộ phần tử là 0 sẽ được tạo bằng 「numpy.zeros」 như trong In[16], còn ma trận có các phần tử là 1 sẽ được tạo bằng 「numpy.ones」 như trong In[17]. Những cái này cũng có thể chỉ định kiểu phần tử bằng dtype.

Chỉ chuẩn bị container của mảng
Trường hợp vì không quan tâm bên trong có gì, nên chuẩn bị sẵn chỉ container của mảng, rồi cho phần tử vào sau, thì sẽ sử dụng 「numpy.empty」 giống In[19]. Cái này thì vì không thực hiện set phần tử bằng cách chỉ chuẩn bị container của mảng, sẽ không biết phần tử của mảng là gì. Thi thoảng khi cấp phát vùng nhớ của mảng, giá trị mà có ở đó sẽ được dùng y nguyên.
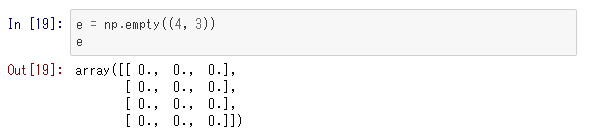
※Chú ý: kết quả này phụ thuộc môi trường, nên nó sẽ không nhất thiết như trên.
Tạo mảng mang phần tử có giá trị ngẫu nhiên
Ở trường hợp thực hện set giá trị khởi tạo, cũng có khi mảng và vector phải mang phần tử ngẫu nhiên. Trường hợp muốn số ngẫu nhiên thống nhất, thì sử dụng 「numpy.random.rand」 như ở In[20], trường hợp muốn số ngẫu nhiên chính quy, thì sẻ dụng 「numpy.random.randn」 như trong In[21].

Ngoài ra, trường hợp muốn đảm bảo tính lặp lại của simulator, sẽ có lúc muốn số ngẫu nhiên giống nhau dù có thực hiện bao nhiêu số ngẫu nhiên đi nữa. Trong trường hợp đó, thì sẽ chỉ định hạt giống của số ngẫu nhiên bằng 「numpy.random.seed」.
Slicing (cắt lát) & Index (chỉ mục)
Cắt lát để trích xuất một phần mảng đã cho
Việc trích xuất một phần mảng đã cho thì sẽ sử dụng một cơ chế là 「slicing (cắt lát)」. Đối với vector (mảng một chiều) 「v」, việc có thể trích xuất một phần bằng 「v[i:j]」「v[i:]」「v[:j]」 v.v… thì giống với list. Ngoài ra, trường hợp là mảng 2 chiều thì sẽ có thể slicing bằng index của từng cái như 「a[i:j,k:l]」 (In[26]:~In[29]:). Về index thì số âm mang ý nghĩa là index được tính từ phía sau. Cái này thì cũng giống với cách sử dụng của list (In[25]:).

Thay đổi hình dạng của ma trận – reshape
「reshape」 ở In[26]: là method để biến đổi hình dạng của ma trận. Nếu là sample code này, vì đang tạo mảng 1 chiều có size 9 bằng 「np.arange(9)」 nên sẽ biến đổi cái đó thành mảng 2 chiều 3×3 bằng 「reshape」.
Lập chỉ mục để trích xuất một loạt nhiều phần tử bằng cách đặt mảng vào trong dấu ngặc đơn của tham chiếu mảng
Bằng việc cho ma trận thể hiện cột index vào trong ngoặc đơn của tham chiếu mảng, có thể trích xuất một loạt nhều phần tử. Thao tác này được gọi là 「index」.

Sử dụng ma trận có phần tử là kiểu Bool bằng index
Ngoài ra, ở index thì ngoài mảng thể hiện cột index, cũng có thể sử dụng mảng có phần tử mang kiểu dữ liệu Bool. Trong trường hợp này, hình dạng của mảng mà có phần tử mang kiểu dữ liệu Bool được cho vào ngoặc đơn và mảng được tham chiếu là phải giống nhau, và những phần tử của bộ phận là True thì sẽ được trích xuất.

Tìm số nhỏ nhất – numpy.min và tìm số lớn nhất – numpy.max
Ngòai ra, 「numpy.min」(số bé nhất)、「numpy.max」(số lớn nhất)、「numpy.argmin」(giá trị index của số bé nhất)、「numpy.argmax」(giá trị index của số lớn nhất) v.v… có cách dùng giống nhau.

Tìm sản phẩm ma trận – numpy.dot
Phép nhân ma trận sử dụng 「numpy.dot」. Ở đây, mảng hai chiều sẽ được coi là ma trận, còn mảng một chiều sẽ được coi là vector. Việc vector 1 chiều được coi là vector cột hay vector hàng thì sẽ được phán định tự động lúc gọi numpy.dot một cách thuận tiện.

Kiểu numpy.matrix thể hiện ma trận
Thực tế thì ở numpy, không chỉ là mảng 2 chiều, mà còn tồn tại cả kiểu 「numpy.matrix」 thể hiện ma trận. Vì mảng 2 chiều thì sẽ là hiệu năng cao, nên kiểu dữ liệu ma trận ít khi được dùng. Vì vậy, mà từ sau này sẽ bỏ qua kiểu dữ liệu ma trận.
Toán tử 「*」
Toán tử 「*」 cũng tồn tại trong ma trận, nhưng không mang ý nghĩa là sản phẩm ma trận, vì vậy mà cần phải chú ý. Đối với 2 mảng giống hình dạng, bốn toán tử có ý nghĩa là tính toán với mỗi phần tử.

Tiếp theo sẽ là về việc sử dụng ma trận và phương pháp tính toán tao nhã
Trong bài viết lần này, tôi đã giới thiệu căn bản của mảng trong NumPy. Đặc biệt, tôi đã tập trung giải thích vào cách đóng gói dữ liệu, cách trích xuất và tính toán đơn giản. Ở bài tiếp theo, tôi sẽ giải thích về việc dùng ma trận, rồi các phương pháp tính toán tao nhã hơn nữa, và về cách sử dụng loại ma trận thưa thớt của SciPy.
Tham khảo: atmarkit

Nhận xét
Đăng nhận xét